Set是一个没有包括重复数据的集合,跟List一样,他们都继承自Collection。
Java中的Set接口最主要的实现类就是HashSet和LinkedHashSet。
HashSet原理分析
首先看下HashSet的属性。
HashSet内部有个HashMap属性和一个对象属性:
private transient HashMap<E,Object> map;
// HashSet内部使用HashMap进行处理,由于Set只需要键值对中的键,而不需要值,所有的值都用这个对象
private static final Object PRESENT = new Object();
HashSet的构造函数中也提供了HashMap的capacity,loadFactor这些参数。
add方法
调用HashMap的put操作完成Set的add操作。
public boolean add(E e) {
return map.put(e, PRESENT)==null; // HashMap put成功返回true,否则false
}
HashMap相关的put操作在之前的博客中已经介绍过了,这里就不分析了。
boolean remove(Object o)
调用HashMap的remove操作完成。
public boolean remove(Object o) {
return map.remove(o)==PRESENT; // 对应的节点移除成功返回true,否则false
}
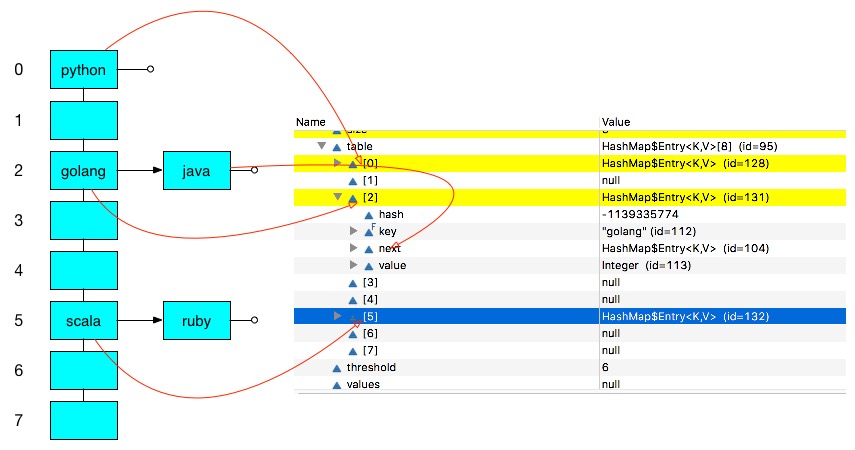
一个HashSet例子
Set<String> set = new HashSet<String>(5);
set.add("java");
set.add("golang");
set.add("python");
set.add("ruby");
set.add("scala");
set.add("c");
for(String str : set) {
System.out.println(str);
}
这个例子中set中的HashMap内部结构如下图所示:
HashSet总结
- HashSet内部使用HashMap,HashSet集合内部所有的操作基本上都是基于HashMap完成的
- HashSet中的元素是无序的,这是因为它内部使用HashMap进行存储,而HashMap添加键值对的时候是根据hash函数得到数组的下标的
LinkedHashSet原理分析
LinkedHashSet继承自HashSet,它的构造函数会调用父类HashSet的构造函数:
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
// map使用LinkedHashMap构造,LinkedHashMap是HashMap的子类,accessOrder为false,即使用插入顺序
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
一个LinkedHashSet例子
Set<String> set = new LinkedHashSet<String>(5);
set.add("java");
set.add("golang");
set.add("python");
set.add("ruby");
set.add("scala");
for(String str : set) {
System.out.println(str);
}
这个例子中set中的LinkedHashMap内部结构如下图所示:

LinkedHashSet总结
- LinkedHashSet继自HashSet,但是内部的map是使用LinkedHashMap构造的,并且accessOrder为false,使用查询顺序。所以LinkedHashSet遍历的顺序就是插入顺序。
