LinkedHashMap是一种会记录插入顺序的Map,内部维护着一个accessOrder属性,用于表示map数据的迭代顺序是基于访问顺序还是插入顺序。
LinkedHashMap原理分析
首先是LinkedHashMap的定义:
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
LinkedHashMap继承HashMap,实现Map接口,所以它的结构跟HashMap是一样的,使用链表法解决哈希冲突的哈希表,基本操作跟HashMap也是一样的,就是多了一点额外的步骤用于处理链表。
LinkedHashMap有个内部类Entry,这个Entry就是链表中的节点,继承自HashMap.Node,多出了2个属性before和after,所以LinkedHashMap内部链表的节点是双向的,代码如下:
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
另外LinkedHashMap还有两个重要的属性head,tail,这2个属性用于存储插入的节点,形成一个双向链表:
// 首节点
transient LinkedHashMap.Entry<K,V> head;
// 尾节点
transient LinkedHashMap.Entry<K,V> tail;
跟HashMap一样,下面这个例子对应的LinkedHashMap结构图示如下所示,accessOrder为false,使用插入顺序:
Map<String, Integer> map = new LinkedHashMap<String, Integer>(5);
map.put("java", 1);
map.put("golang", 2);
map.put("python", 3);
map.put("ruby", 4);
map.put("scala", 5);

put操作
LinkedHashMap没有覆盖HashMap的put方法,所以put操作跟HashMap是一样的。但是它覆盖了newNode方法,也就是说构造新节点的时候,LinkedHashMap跟HashMap是不一样的:
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
// 使用Entry双向链表构造节点,而不是HashMap的Node单向链表
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p); // 更新双向链表,这一操作在HashMap里面是没有的
return p;
}
另外,LinkedHashMap重写了afterNodeInsertion这个钩子方法,在put一个关键字不存在的节点之后会调用这个方法:
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
// removeEldestEntry方法LinkedHashMap永远返回false,一些使用缓存策略的Map会覆盖这个方法,比如jackson的LRUMap,会移除最老的节点,也就是首节点
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
put操作如果关键字已经存在,会调用afterNodeAccess这个钩子方法:
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) { // 如果使用访问顺序并且访问的不是尾节点
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
get操作
LinkedHashMap复写了get方法:
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder) // 使用访问顺序的话,调用afterNodeAccess方法
afterNodeAccess(e);
return e.value;
}
remove操作
LinkedHashMap的remove方法没有复写HashMap的remove方法,但是同样实现了afterNodeRemoval这个钩子方法:
// 更新双向链表
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}
accessOrder属性分析
LinkedHashMap默认情况下,accessOrder属性为false,也就是使用插入顺序,这个插入顺序是根据LinkedHashMap内部的一个双向链表实现的。如果accessOrder为true,也就是使用访问顺序,那么afterNodeAccess这个钩子方法内部的逻辑会被执行,将会修改双向链表的结构,再来看一下这个方法的具体逻辑:
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) { // 使用访问顺序,把节点移动到双向链表的最后面,如果已经在最后面了,不需要进行移动
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a; // 特殊情况,处理头节点
else
b.after = a; // 节点处理
if (a != null)
a.before = b; // 节点处理
else
last = b; // 特殊情况,处理尾节点
if (last == null)
head = p;
else {
p.before = last; // 尾节点处理
last.after = p;
}
tail = p;
++modCount;
}
}
afterNodeAccess在使用get方法或者put方法遇到关键字已经存在的情况下,会被触发,一个例子如下:
Map<String, Integer> map = new LinkedHashMap<String, Integer>(5, 0.75f, true);
map.put("java", 1);
map.put("golang", 2);
map.put("python", 3);
map.put("ruby", 4);
map.put("scala", 5);
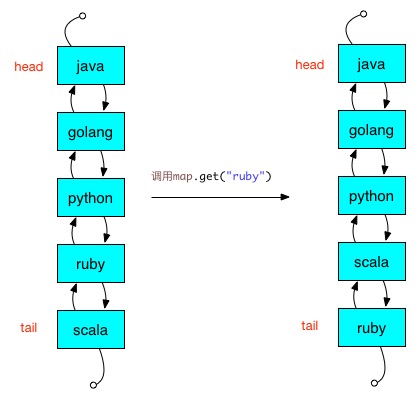
System.out.println(map.get("ruby"));
上面这段代码,LinkedHashMap的accessOrder属性为true,使用访问顺序,最后调用了get方法,触发afterNodeAccess方法,修改双向链表,效果如下:
注意点
LinkedHashMap使用访问顺序并且进行遍历的时候,如果使用如下代码,会发生ConcurrentModificationException异常:
for(String str : map.keySet()) {
System.out.println(map.get(str));
}
不应该这么使用,而是应该直接读取value:
for(Integer it : map.values()) {
System.out.println(it);
}
具体可以参考stackoverflow上的这篇帖子。
总结
LinkedHashMap也是一种使用拉链式哈希表的数据结构,除了哈希表,它内部还维护着一个双向链表,用于处理访问顺序和插入顺序的问题
LinkedHashMap继承自HashMap,大多数的方法都是跟HashMap一样的,不过覆盖了一些方法
