一般情况下,我们使用java开发springboot应用,可以使用scala开发springboot应用吗?
答案当然是可以的。
今天参考了阿福老师的这篇Scala开发者的SpringBoot快速入门指南以及一位国际友人的一个spring-boot-scala-web demo。
自己尝试地搭建了一下环境,发现用scala编写springboot应用这种体验也是非常赞的。
下面是具体的环境搭建流程:
一般情况下,我们使用java开发springboot应用,可以使用scala开发springboot应用吗?
答案当然是可以的。
今天参考了阿福老师的这篇Scala开发者的SpringBoot快速入门指南以及一位国际友人的一个spring-boot-scala-web demo。
自己尝试地搭建了一下环境,发现用scala编写springboot应用这种体验也是非常赞的。
下面是具体的环境搭建流程:
springboot用来简化Spring框架带来的大量XML配置以及复杂的依赖管理,让开发人员可以更加关注业务逻辑的开发。
比如不使用springboot而使用SpringMVC作为web框架进行开发的时候,需要配置相关的SpringMVC配置以及对应的依赖,比较繁琐;而使用springboot的话只需要以下短短的几行代码就可以使用SpringMVC,可谓相当地方便:
@RestController
class App {
@RequestMapping("/")
String home() {
"hello"
}
}
其中maven配置如下:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.3.5.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
Java线程的生命周期中,存在几种状态。在Thread类里有一个枚举类型State,定义了线程的几种状态,分别有:
Java中的阻塞队列接口BlockingQueue继承自Queue接口。
BlockingQueue接口提供了3个添加元素方法。
3个删除方法。
常用的阻塞队列具体类有ArrayBlockingQueue、LinkedBlockingQueue、PriorityBlockingQueue、LinkedBlockingDeque等。
本文以ArrayBlockingQueue和LinkedBlockingQueue为例,分析它们的实现原理。
CountDownLatch和CyclicBarrier都是java并发包下的工具类。
CountDownLatch用于处理一个或多个线程等待其他所有线程完毕之后再继续进行操作。
比如要处理一个非常耗时的任务,处理完之后需要更新这个任务的状态,需要开多线程去分批次处理任务中的各个子任务,当所有的子任务全部执行完毕之后,就可以更新任务状态了。这个时候就需要使用CountDownLatch。
CyclicBarrier用于N个线程相互等待,当到达条件之后所有线程继续执行。
比如一个抽奖活动,每个线程进行抽奖,当奖品全部抽完之后对各个线程中的用户进行后续操作。
个人理解的两者之间的区别有3点:
Java提供了很多同步操作,比如synchronized关键字、wait/notifyAll、ReentrantLock、Condition、一些并发包下的工具类、Semaphore,ThreadLocal、AbstractQueuedSynchronizer等。
本文简单说明一下这几种方式的使用。

ConcurrentSkipListMap是一个内部使用跳表,并且支持排序和并发的一个Map。
跳表的介绍:
跳表是一种允许在一个有顺序的序列中进行快速查询的数据结构。
如果在普通的顺序链表中查询一个元素,需要从链表头部开始一个一个节点进行遍历,然后找到节点,如下图所示,要查找234元素的话需要从5元素节点开始一个一个节点进行遍历,这样的效率是非常低的。

跳表可以解决这种查询时间过长的问题:
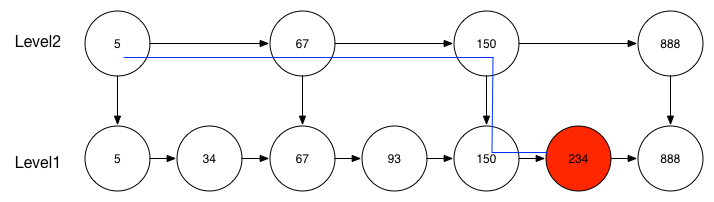
从上图可以看到,跳表具有以下几种特性:
使用跳表查询元素的时间复杂度是O(log n),跟红黑树一样。查询效率还是不错的,
但是跳表的存储容量变大了,本来一共只有7个节点的数据,使用跳表之后变成了14个节点。
所以跳表是一种使用”空间换时间”的概念用来提高查询效率的链表,开源软件Redis、LevelDB都使用到了跳表。跳表相比B树,红黑树,AVL树时间复杂度一样,但是耗费更多存储空间,但是跳表的优势就是它相比树,实现简单,不需要考虑树的一些rebalance问题。
优先队列跟普通的队列不一样,普通队列是一种遵循FIFO规则的队列,拿数据的时候按照加入队列的顺序拿取。 而优先队列每次拿数据的时候都会拿出优先级最高的数据。
优先队列内部维护着一个堆,每次取数据的时候都从堆顶拿数据,这就是优先队列的原理。
jdk的优先队列使用PriorityQueue这个类,使用者可以自己定义优先级规则。
堆的概念:
n个元素序列 { k1, k2, k3, k4, k5, k6 …. kn } 当且仅当满足以下关系时才会被称为堆:
ki <= k2i,ki <= k2i+1 或者 ki >= k2i,ki >= k2i+1 (i = 1,2,3,4 .. n/2)
如果数组的下表是从0开始,那么需要满足
ki <= k2i+1,ki <= k2i+2 或者 ki >= k2i+1,ki >= k2i+2 (i = 0,1,2,3 .. n/2)
比如 { 1,3,5,10,15,9 } 这个序列就满足 [1 <= 3; 1 <= 5], [3 <= 10; 3 <= 15], [5 <= 9] 这3个条件,这个序列就是一个堆。
所以堆其实是一个序列(数组),如果这个序列满足上述条件,那么就把这个序列看成堆。
堆的实现通常是通过构造二叉堆,因为二叉堆应用很普遍,当不加限定时,堆通常指的就是二叉堆。
TreeSet跟HashSet,LinkedHashSet一样,都是Set接口的实现类。
HashSet内部使用的HashMap,LinkedHashSet继承HashSet,内部使用的是LinkedHashMap。
TreeSet实现的是NavigableSet接口,而不是HashSet和LinkedHashSet实现的Set接口。
NavigableSet接口继承自SortedSet接口,SortedSet接口继承自Set接口。
NavigableSet接口比Set更方便,可以使用firstKey[最小关键字],lastKey[最大关键字],pollFirstEntry[最小键值对],pollLastEntry[最大键值对],higherEntry[比参数关键字要大的键值对],lowerEntry[比参数关键字要小的键值对]等等方便方法,可以使用这些方法方便地获取期望位置上的键值对。