TreeSet跟HashSet,LinkedHashSet一样,都是Set接口的实现类。
HashSet内部使用的HashMap,LinkedHashSet继承HashSet,内部使用的是LinkedHashMap。
TreeSet实现的是NavigableSet接口,而不是HashSet和LinkedHashSet实现的Set接口。
NavigableSet接口继承自SortedSet接口,SortedSet接口继承自Set接口。
NavigableSet接口比Set更方便,可以使用firstKey[最小关键字],lastKey[最大关键字],pollFirstEntry[最小键值对],pollLastEntry[最大键值对],higherEntry[比参数关键字要大的键值对],lowerEntry[比参数关键字要小的键值对]等等方便方法,可以使用这些方法方便地获取期望位置上的键值对。
TreeSet原理分析
TreeSet跟HashSet一样,内部都使用Map,HashSet内部使用的是HashMap,但是TreeSet使用的是NavigableMap。
TreeSet的几个构造方法会构造NavigableMap,如果使用没有参数的构造函数,NavigableMap是TreeMap:
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
}
public TreeSet() {
this(new TreeMap<E,Object>());
}
public TreeSet(Comparator<? super E> comparator) {
this(new TreeMap<>(comparator));
}
add方法调用Map的put方法:
public boolean add(E e) {
return m.put(e, PRESENT)==null;
}
remove方法调用Map的remove方法:
public boolean remove(Object o) {
return m.remove(o)==PRESENT;
}
原理基本跟HashSet一样。
// 最小的关键字
public E first() {
return m.firstKey();
}
// 最大的关键字
public E last() {
return m.lastKey();
}
// 比参数小的关键字
public E lower(E e) {
return m.lowerKey(e);
}
一个TreeSet例子
使用没有参数的TreeMap构造函数,内部的Map使用TreeMap红黑树:
TreeSet<String> set = new TreeSet<String>();
set.add("1:语文");
set.add("2:数学");
set.add("3:英语");
set.add("4:政治");
set.add("5:物理");
set.add("6:化学");
set.add("7:生物");
set.add("8:体育");
内部红黑树结构如下:
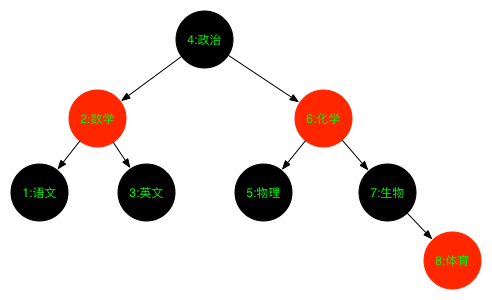
还可以调用TreeSet的其他方法:
set.first(); // 1:语文
set.last(); // 8:体育
set.higher("5:物理"); // 6:化学
set.lower("5:物理"); // 4:政治
