优先队列跟普通的队列不一样,普通队列是一种遵循FIFO规则的队列,拿数据的时候按照加入队列的顺序拿取。 而优先队列每次拿数据的时候都会拿出优先级最高的数据。
优先队列内部维护着一个堆,每次取数据的时候都从堆顶拿数据,这就是优先队列的原理。
jdk的优先队列使用PriorityQueue这个类,使用者可以自己定义优先级规则。
一个PriorityQueue例子
定义一个Task类,有2个属性name和level。这个类放到PriorityQueue里,level越大优先级越高:
private static class Task {
String name;
int level;
public Task(String name, int level) {
this.name = name;
this.level = level;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getLevel() {
return level;
}
public void setLevel(int level) {
this.level = level;
}
@Override
public String toString() {
return "Task{" +
"name='" + name + '\'' +
", level=" + level +
'}';
}
}
public static void main(String[] args) {
PriorityQueue<Task> queue = new PriorityQueue<Task>(6, new Comparator<Task>() {
@Override
public int compare(Task t1, Task t2) {
return t2.getLevel() - t1.getLevel();
}
});
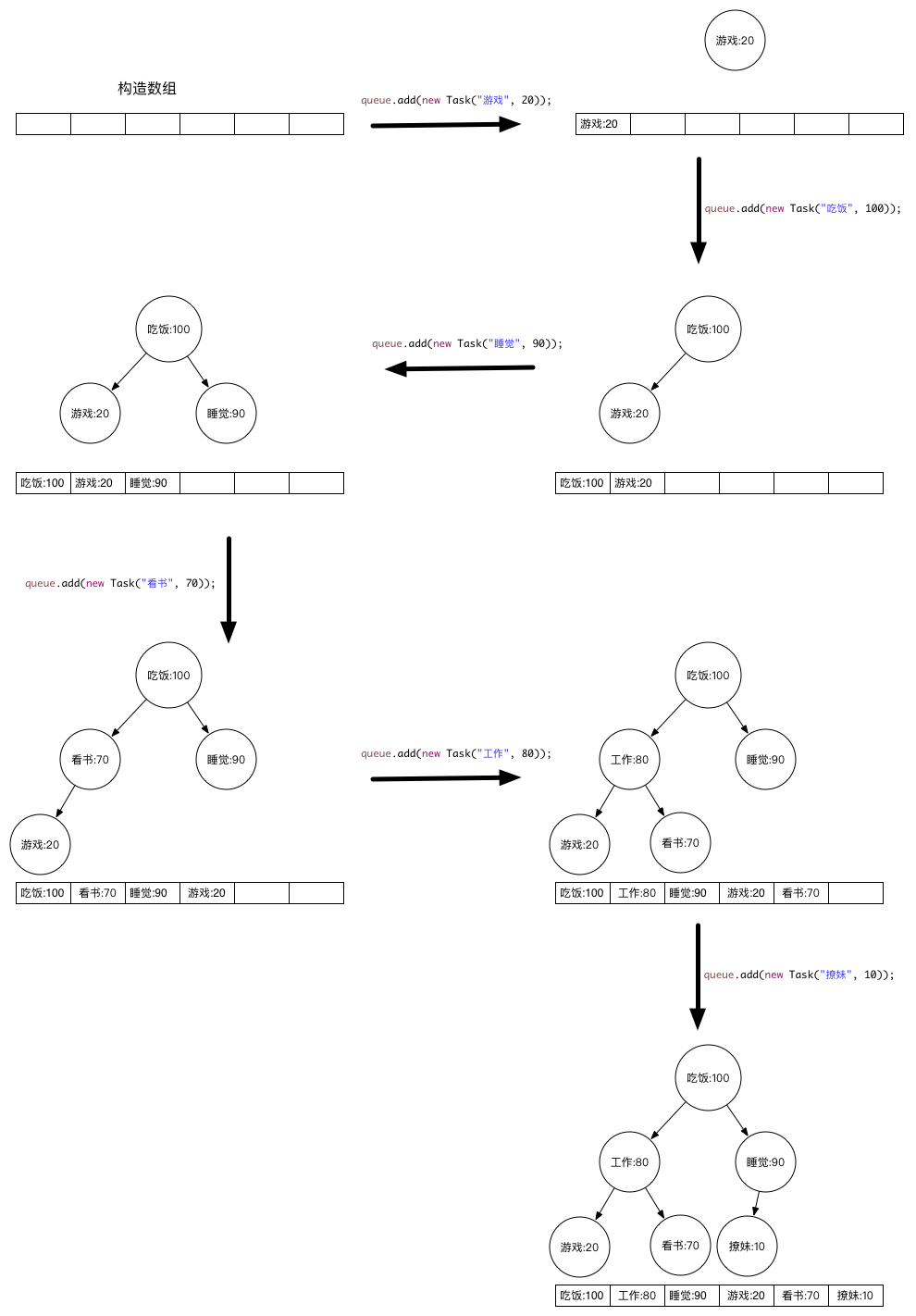
queue.add(new Task("游戏", 20));
queue.add(new Task("吃饭", 100));
queue.add(new Task("睡觉", 90));
queue.add(new Task("看书", 70));
queue.add(new Task("工作", 80));
queue.add(new Task("撩妹", 10));
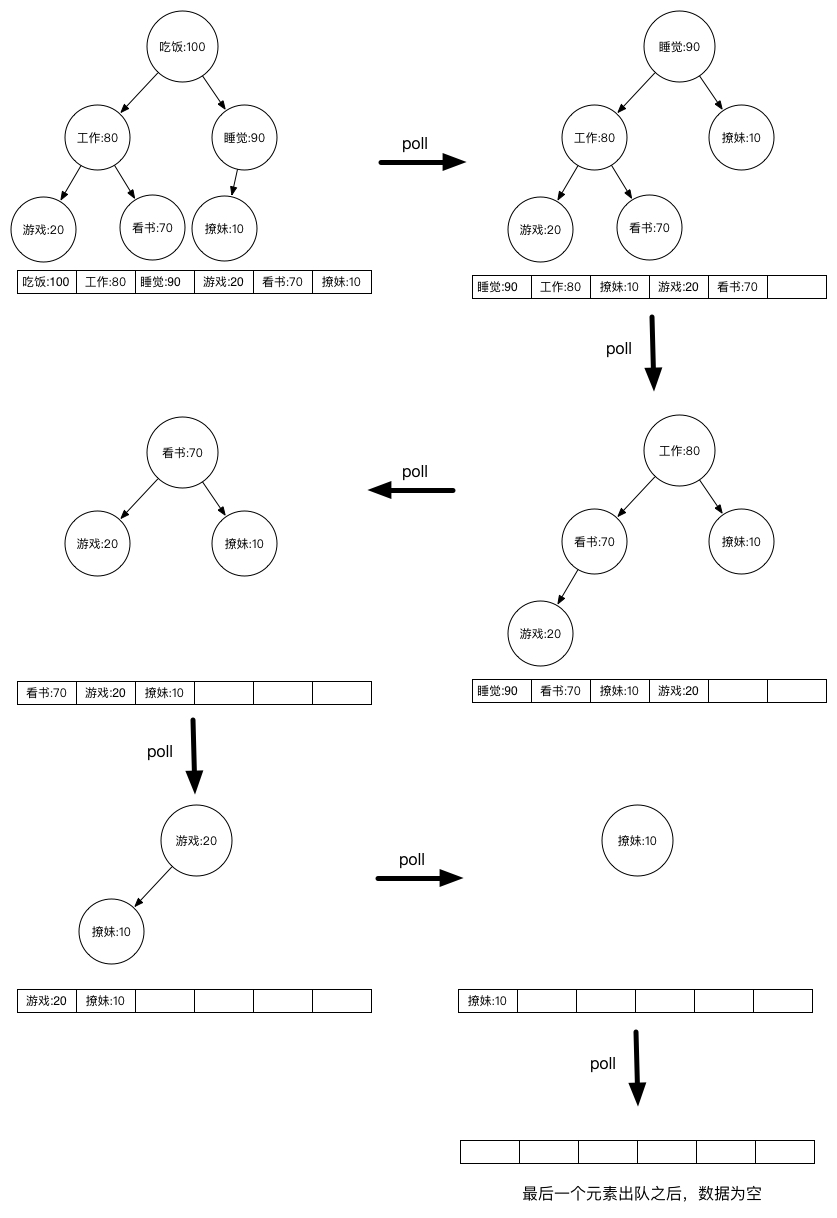
while(!queue.isEmpty()) {
System.out.println(queue.poll());
}
}
输出结果:
Task{name='吃饭', level=100}
Task{name='睡觉', level=90}
Task{name='工作', level=80}
Task{name='看书', level=70}
Task{name='游戏', level=20}
Task{name='撩妹', level=10}
add过程其实就是在最大堆里添加新的元素,添加之后再进行调整:
出队相当于每次都是堆顶出堆,堆顶出堆之后然后重新调整:
PriorityQueue原理分析
首先看下PriorityQueue的属性:
transient Object[] queue; // 堆
private int size = 0; // 元素个数
private final Comparator<? super E> comparator; // 比较器,如果是null,使用元素自身的比较器
接下来是PriorityQueue的几个方法介绍。
add,添加元素:
public boolean add(E e) {
return offer(e); // add方法内部调用offer方法
}
public boolean offer(E e) {
if (e == null) // 元素为空的话,抛出NullPointerException异常
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length) // 如果当前用堆表示的数组已经满了,调用grow方法扩容
grow(i + 1); // 扩容
size = i + 1; // 元素个数+1
if (i == 0) // 堆还没有元素的情况
queue[0] = e; // 直接给堆顶赋值元素
else // 堆中已有元素的情况
siftUp(i, e); // 重新调整堆,从下往上调整,因为新增元素是加到最后一个叶子节点
return true;
}
private void siftUp(int k, E x) {
if (comparator != null) // 比较器存在的情况下
siftUpUsingComparator(k, x); // 使用比较器调整
else // 比较器不存在的情况下
siftUpComparable(k, x); // 使用元素自身的比较器调整
}
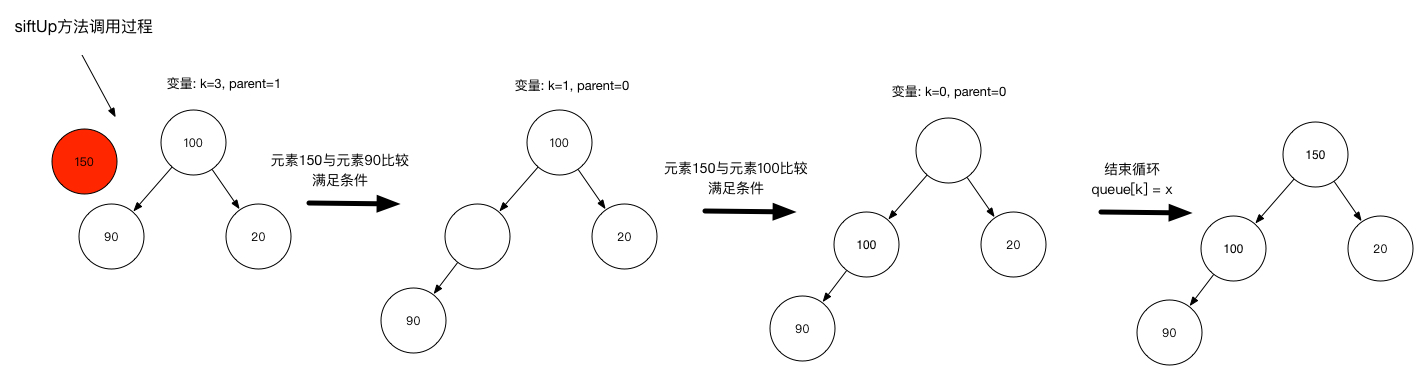
private void siftUpUsingComparator(int k, E x) {
while (k > 0) { // 一直循环直到父节点还存在
int parent = (k - 1) >>> 1; // 找到父节点索引
Object e = queue[parent]; // 赋值父节点元素
if (comparator.compare(x, (E) e) >= 0) // 新元素与父元素进行比较,如果满足比较器结果,直接跳出,否则进行调整
break;
queue[k] = e; // 进行调整,新位置的元素变成了父元素
k = parent; // 新位置索引变成父元素索引,进行递归操作
}
queue[k] = x; // 新添加的元素添加到堆中
}
siftUp方法调用过程如下:
poll,出队方法:
public E poll() {
if (size == 0)
return null;
int s = --size; // 元素个数-1
modCount++;
E result = (E) queue[0]; // 得到堆顶元素
E x = (E) queue[s]; // 最后一个叶子节点
queue[s] = null; // 最后1个叶子节点置空
if (s != 0)
siftDown(0, x); // 从上往下调整,因为删除元素是删除堆顶的元素
return result;
}
private void siftDown(int k, E x) {
if (comparator != null) // 比较器存在的情况下
siftDownUsingComparator(k, x); // 使用比较器调整
else // 比较器不存在的情况下
siftDownComparable(k, x); // 使用元素自身的比较器调整
}
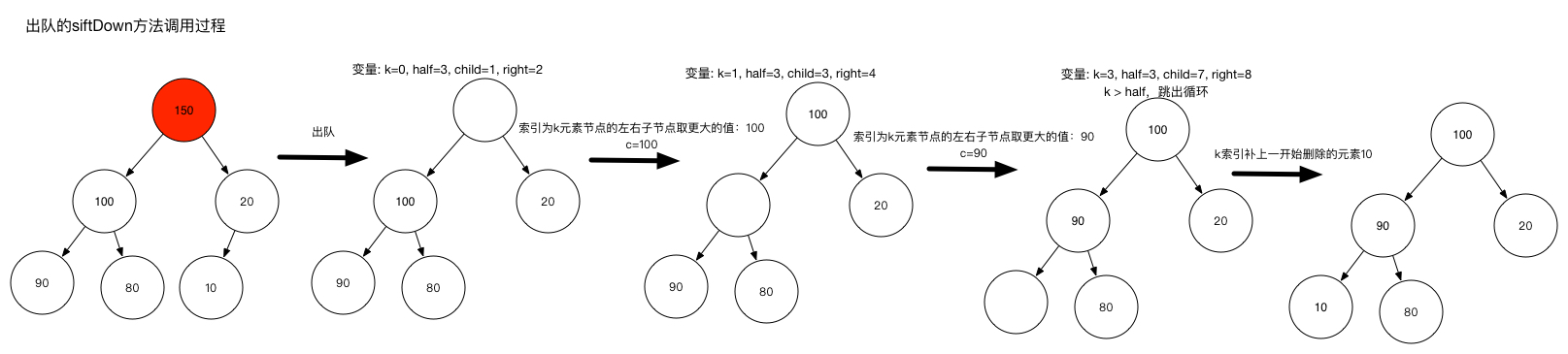
private void siftDownUsingComparator(int k, E x) {
int half = size >>> 1; // 只需循环节点个数的一般即可
while (k < half) {
int child = (k << 1) + 1; // 得到父节点的左子节点索引
Object c = queue[child]; // 得到左子元素
int right = child + 1; // 得到父节点的右子节点索引
if (right < size &&
comparator.compare((E) c, (E) queue[right]) > 0) // 左子节点跟右子节点比较,取更大的值
c = queue[child = right];
if (comparator.compare(x, (E) c) <= 0) // 然后这个更大的值跟最后一个叶子节点比较
break;
queue[k] = c; // 新位置使用更大的值
k = child; // 新位置索引变成子元素索引,进行递归操作
}
queue[k] = x; // 最后一个叶子节点添加到合适的位置
}
siftDown方法调用过程如下:
grow扩容方法:
private void grow(int minCapacity) {
int oldCapacity = queue.length;
// 新容量
// 如果老容量小于64 新容量 = 老容量 + 老容量 + 2
// 如果老容量大于等于64 老容量 = 老容量 + 老容量/2
int newCapacity = oldCapacity + ((oldCapacity < 64) ?
(oldCapacity + 2) :
(oldCapacity >> 1));
// 溢出处理
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// 使用新容量
queue = Arrays.copyOf(queue, newCapacity);
}
remove,删除队列元素操作:
public boolean remove(Object o) {
int i = indexOf(o); // 找到数据对应的索引
if (i == -1) // 不存在的话返回false
return false;
else { // 存在的话调用removeAt方法,返回true
removeAt(i);
return true;
}
}
private E removeAt(int i) {
modCount++;
int s = --size; // 元素个数-1
if (s == i) // 如果是删除最后一个叶子节点
queue[i] = null; // 直接置空,删除即可,堆还是保持特质,不需要调整
else { // 如果是删除的不是最后一个叶子节点
E moved = (E) queue[s]; // 获得最后1个叶子节点元素
queue[s] = null; // 最后1个叶子节点置空
siftDown(i, moved); // 从上往下调整
if (queue[i] == moved) { // 如果从上往下调整完毕之后发现元素位置没变,从下往上调整
siftUp(i, moved); // 从下往上调整
if (queue[i] != moved)
return moved;
}
}
return null;
}
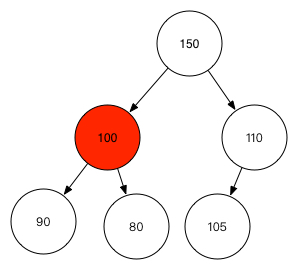
下图这个堆如果删除红色节点100的时候,siftDown之后元素位置没变,所以还得siftUp:
总结
- jdk内置的优先队列PriorityQueue内部使用一个堆维护数据,每当有数据add进来或者poll出去的时候会对堆做从下往上的调整和从上往下的调整
- PriorityQueue不是一个线程安全的类,如果要在多线程环境下使用,可以使用PriorityBlockingQueue这个优先阻塞队列
