ConcurrentSkipListMap是一个内部使用跳表,并且支持排序和并发的一个Map。
跳表的介绍:
跳表是一种允许在一个有顺序的序列中进行快速查询的数据结构。
如果在普通的顺序链表中查询一个元素,需要从链表头部开始一个一个节点进行遍历,然后找到节点,如下图所示,要查找234元素的话需要从5元素节点开始一个一个节点进行遍历,这样的效率是非常低的。

跳表可以解决这种查询时间过长的问题:
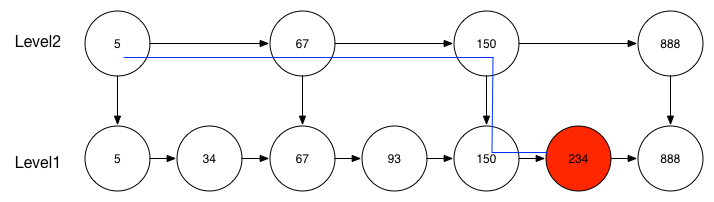
从上图可以看到,跳表具有以下几种特性:
- 由很多层组成,level越高的层节点越少,最后一层level用有所有的节点数据
- 每一层的节点数据也都是有顺序的
- 上面层的节点肯定会在下面层中出现
- 每个节点都有两个指针,分别是同一层的下一个节点指针和下一层节点的指针
使用跳表查询元素的时间复杂度是O(log n),跟红黑树一样。查询效率还是不错的,
但是跳表的存储容量变大了,本来一共只有7个节点的数据,使用跳表之后变成了14个节点。
所以跳表是一种使用”空间换时间”的概念用来提高查询效率的链表,开源软件Redis、LevelDB都使用到了跳表。跳表相比B树,红黑树,AVL树时间复杂度一样,但是耗费更多存储空间,但是跳表的优势就是它相比树,实现简单,不需要考虑树的一些rebalance问题。
下图是一个级别更高的跳表:
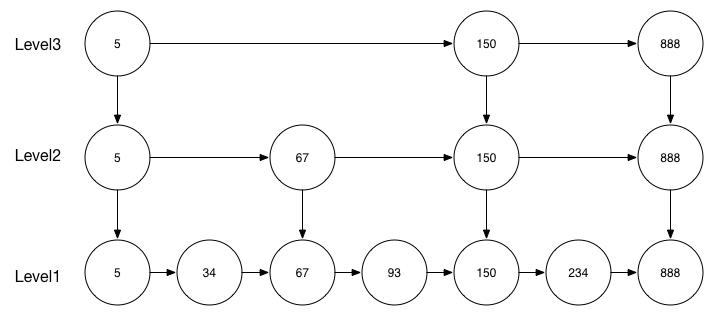
跳表的查询
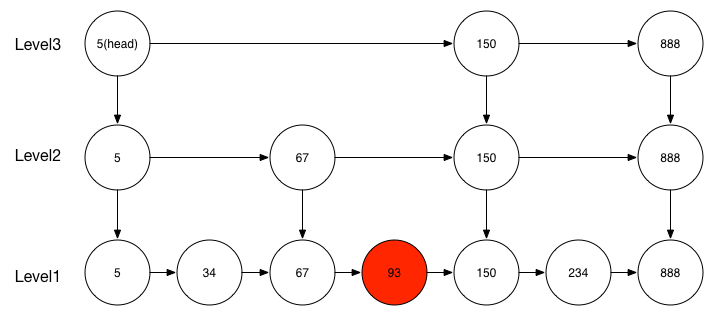
比如要在下面这个跳表中查找93元素,过程如下:
- 从head节点(最上层的第一个节点)开始找,发现5比93小,继续同一层(Level3)的下一个节点150进行比较
- 发现105比93大,往下一层(Level2)走,然后找Level2的5元素的下一个节点67,发现67比93小,继续同一层(Level2)的下一个节点150进行比较
- 发现105比93大,往下一层(Level1)走,然后找Level1的67元素的下一个节点93,找到,返回
跳表新增元素
跳表中新增元素的话首先会确定Level层,在这个Level以及这个Level以下的层中都加入新的元素,具体的Level层数是通过一个通过一种随机算法获取的,比如之前这个跳表在Level2和Level1中插入666元素:
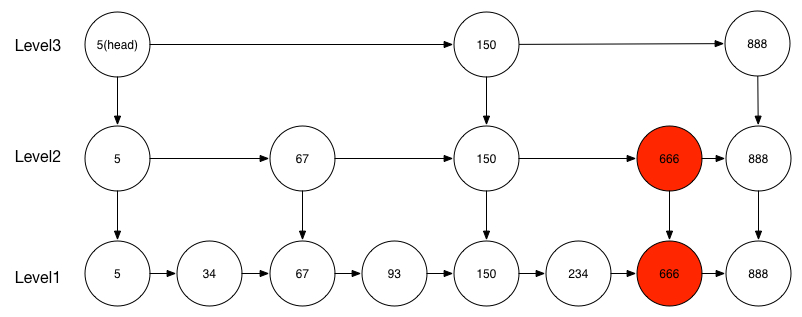
如果Level大于目前跳表的层数,那么会添加新的一层。
跳表删除元素
在各个层中找到对应的元素并删除即可。
ConcurrentSkipListMap分析
ConcurrentSkipListMap对跳表中的几个概念做了一层封装,如下:
// 每个节点的封装,跟层数没有关系
static final class Node<K,V> {
final K key; // 节点的关键字
volatile Object value; // 节点的值
volatile Node<K,V> next; // 节点的next节点引用
...
}
// 每一层节点的封装,叫做索引
static class Index<K,V> {
final Node<K,V> node; // 对应的节点
final Index<K,V> down; // 下一层索引
volatile Index<K,V> right; // 同一层的下一个索引
...
}
// 每一层的头索引
static final class HeadIndex<K,V> extends Index<K,V> {
final int level; // Level 级别
HeadIndex(Node<K,V> node, Index<K,V> down, Index<K,V> right, int level) {
super(node, down, right);
this.level = level;
}
...
}
简单分析下ConcurrentSkipListMap的get方法:
private V doGet(Object key) {
if (key == null)
throw new NullPointerException();
Comparator<? super K> cmp = comparator;
outer: for (;;) {
// findPredecessor方法表示找到最接近要查找节点的节点,并且这个节点在最下面那一层,这样就保证会遍历所有节点
for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) {
Object v; int c;
if (n == null) // 已经遍历节点到最后还是没有找到,break,返回null
break outer;
Node<K,V> f = n.next;
if (n != b.next) // 判断比较下一个节点是否发生了变化,如果发生变化break重新开始死循环
break;
if ((v = n.value) == null) { // 如果下一个节点已经被删除了
n.helpDelete(b, f);
break;
}
if (b.value == null || v == n) // b is deleted
break;
if ((c = cpr(cmp, key, n.key)) == 0) { // 比较并且找到了,直接返回
@SuppressWarnings("unchecked") V vv = (V)v;
return vv;
}
if (c < 0) // 找过头了,说明没有对应节点了,跳出循环,返回null
break outer;
b = n; // 继续遍历
n = f; // 继续遍历
}
}
return null;
}
private Node<K,V> findPredecessor(Object key, Comparator<? super K> cmp) {
if (key == null)
throw new NullPointerException(); // don't postpone errors
for (;;) { // 一个死循环内部套着另外一个循环
for (Index<K,V> q = head, r = q.right, d;;) { // head表示最顶层的第一个索引,从这个索引开始找
if (r != null) { // 如果索引的同一层下一个索引不为null
Node<K,V> n = r.node;
K k = n.key;
if (n.value == null) { // 如果是个已删除节点
if (!q.unlink(r)) // 使用cas把已删除节点从跳表上删除掉
break; // 已删除节点从跳表上删除失败,跳出重新循环
r = q.right; // 继续遍历
continue;
}
if (cpr(cmp, key, k) > 0) { // 使用cas比较要找的关键字和索引内节点的关键字,如果满足比较条件
q = r; // 当前所在索引变成同一层下一个索引
r = r.right; // 当前所在索引的下一个索引变成下下个索引,继续遍历
continue;
}
}
// 直到找出上一层满足不了条件的那个索引
if ((d = q.down) == null) // 找到下一层的索引
return q.node; // 如果下一层没有索引了,返回找到的最接近的节点
q = d; // 下一层开始做相同的操作
r = d.right; // 下一层开始做相同的操作
}
}
}
