List接口的实现类之一ArrayList的内部实现是一个数组,而另外一个实现LinkedList内部实现是使用双向链表。
LinkedList在内部定义了一个叫做Node类型的内部类,这个Node就是一个节点,链表中的节点,这个节点有3个属性,分别是元素item(当前节点要表示的值), 前节点prev(当前节点之前位置上的一个节点),后节点next(当前节点后面位置的一个节点)。
LinkedList关于数据的插入,删除操作都会处理这些节点的前后关系。而不像ArrayList那样只需要移动元素的位置即可。
源码分析
在分析LinkedList之前,我们先看下它里面的内部类Node,也就是节点的定义:
private static class Node<E> {
E item; // 节点所表示的值
Node<E> next; // 后节点
Node<E> prev; // 前节点
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
LinkedList的3个属性:
transient int size = 0; // 集合链表内节点数量
transient Node<E> first; // 集合链表的首节点
transient Node<E> last; // 集合链表的尾节点
add(E e)
添加元素到链表的最后一个位置
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null); // 由于是添加元素的链表尾部,所以也就是这个新的节点是最后1个节点,它的前节点肯定是目前链表的尾节点,它的后节点为null
last = newNode; // 尾节点变成新的节点
if (l == null) // 如果一开始尾节点还没设置,那么说明这个新的节点是第一个节点,那么首节点也就是这个第一个节点
first = newNode;
else // 否则,说明新节点不是第一个节点,处理节点前后关系
l.next = newNode;
size++; // 节点数量+1
modCount++;
}
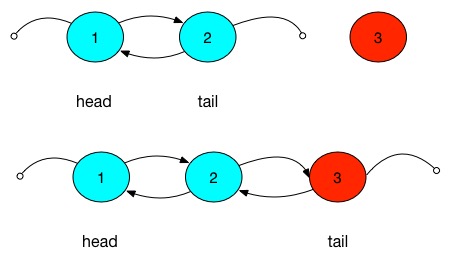
上图第一个图就表示一个已经有1,2这2个节点的LinkedList调用add方法,第二个图表示添加一个值为3的元素后的情况。原先的尾节点2的后节点变成的新节点3,新节点3的前节点是原先的尾节点2,新节点3的后节点为null。同时链表的尾节点变成了3.
add(int index, E element)
添加元素到列表中的指定位置
public void add(int index, E element) {
checkPositionIndex(index); // 检查索引的合法性,不能超过链表个数,不能小于0
if (index == size) // 如果是在链表尾部插入节点,那么直接调用linkLast方法,上面已经分析过
linkLast(element);
else // 不在链表尾部插入节点的话,调用linkBefore方法,参数为要插入的元素值和节点对象
linkBefore(element, node(index));
}
先看一下node方法是如何根据索引找到对应的节点的:
Node<E> node(int index) {
// 用了一个小算法,如果索引比链表数量的一半还要小,从前往后找,这样只需要花O(n/2)的时间获取节点
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else { // 否则从后往前找
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
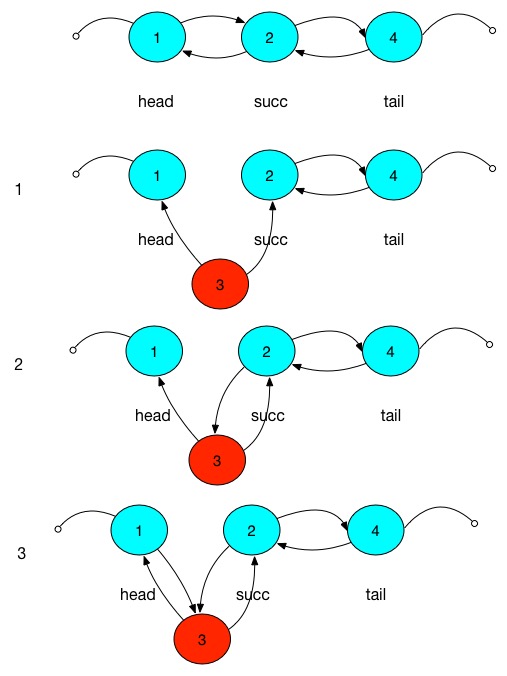
void linkBefore(E e, Node<E> succ) { // succ节点表示要新插入节点应该在的位置
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ); // 1:新节点的前节点就是succ节点的前节点,新节点的后节点是succ节点
succ.prev = newNode; // 2:succ的前节点就是新节点
if (pred == null) // prev=null表示succ节点就是head首节点,这样的话只需要重新set一下首节点即可,首节点的后节点在步骤1以及设置过了
first = newNode;
else // succ不是首节点的话执行步骤3
pred.next = newNode; // 3:succ节点的前节点的后节点就是新节点
size++; // 节点数量+1
modCount++;
}
上面代码中注释的1,2,3点就在下图中表示:
LinkedList还提供了2种特殊的add方法,分别是addFirst和addLast方法,处理添加首节点和尾节点,原理都是差不多的,处理链表之间的关联关系即可。
remove(int index)
移除指定位置上的节点
public E remove(int index) {
checkElementIndex(index); // 检查索引的合法性,不能超过链表个数,不能小于0
return unlink(node(index));
}
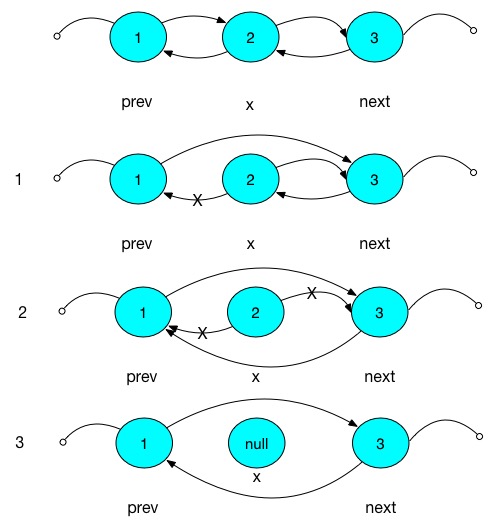
E unlink(Node<E> x) {
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) { // 特殊情况,删除的是头节点
first = next;
} else {
prev.next = next; // 1
x.prev = null; // 1
}
if (next == null) { // 特殊情况,删除的是尾节点
last = prev;
} else {
next.prev = prev; // 2
x.next = null; // 2
}
x.item = null; // 3
size--; // 链表数量减一
modCount++;
return element;
}
上面代码中注释的1,2,3点就在下图中表示:
get(int index)
得到索引位置上的元素
public E get(int index) {
checkElementIndex(index); // 检查索引的合法性,不能超过链表个数,不能小于0
return node(index).item; // 直接找到节点,返回节点的元素值即可
}
LinkedList和ArrayList的比较
- LinkedList和ArrayList的设计理念完全不一样,ArrayList基于数组,而LinkedList基于节点,也就是链表。所以LinkedList内部没有容量这个概念,因为是链表,链表是无界的
- 两者的使用场景不同,ArrayList适用于读多写少的场合。LinkedList适用于写多读少的场合。 刚好相反。 那是因为LinkedList要找节点的话必须要遍历一个一个节点,直到找到为止。而ArrayList完全不需要,因为ArrayList内部维护着一个数组,直接根据索引拿到需要的元素即可。
- 两个都是List接口的实现类,都是一种集合
