Flume的这个问题纠结了2个月,因为之前实在太忙了,没有时间来研究这个问题产生的原理,今天终于研究出来了,找出了这个问题所在。
先来描述一下这个问题的现象:
Flume的Source用的是KafkaSource,Sink用的是Custom Sink,由于这个Custom Sink写的有一点小问题,比如batchSize是5000次,第4000条就会发生exception,这样每次都会写入4000条数据。Sink处理的时候都会发生异常,每次都会rollback,rollback方面的知识可以参考Flume Transaction介绍。
这样造成的后果有3个:
1.Channel中的数据满了。会发生以下异常:
Caused by: org.apache.flume.ChannelFullException: Space for commit to queue couldn't be acquired. Sinks are likely not keeping up with sources, or the buffer size is too tight
2.Sink会一直写数据,造成数据量暴增。
3.如果用了interceptor,且修改了event中的数据,那么会重复处理这些修改完后的event数据。
前面2个很容易理解,Sink发生异常,transaction rollback,导致channel中的队列满了。
关键是第三点,很让人费解。
以一段伪需求和伪代码为例,TestInterceptor的intercept方法:
比如处理一段json:
{"name": "format", "languages": ["java", "scala", "javascript"]}
使用interceptor处理成:
[{"name": "format", "language": "java"}, {"name": "format", "language": "scala"}, {"name": "format", "language": "javascript"}]
interceptor代码如下:
public Event intercept(Event event) {
Model model = null;
String jsonStr = new String(event.getBody(), "UTF-8");
try {
model = parseJsonStr(jsonStr);
} catch (Exception e) {
log.error("convert json data error");
}
event.setBody(model.getJsonString().getBytes());
return event;
}
当Channel中的队列已经满了以后,上述代码会打印出convert json data error,而且jsonStr的内容居然是转换后的数据,这一点一开始让我十分费解,误以为transaction rollback之后会修改source中的数据。后来debug源码发现错误在Source中。
后来发现并不是这样的。
KafkaSource中有一个属性eventList,是个ArrayList。用来接收kafka consume的message。
直接说明KafkaSource的process方法源码:
public Status process() throws EventDeliveryException {
byte[] kafkaMessage;
byte[] kafkaKey;
Event event;
Map<String, String> headers;
long batchStartTime = System.currentTimeMillis();
long batchEndTime = System.currentTimeMillis() + timeUpperLimit;
try {
/** 这里读取kafka中的message **/
boolean iterStatus = false;
while (eventList.size() < batchUpperLimit &&
System.currentTimeMillis() < batchEndTime) {
iterStatus = hasNext();
if (iterStatus) {
// get next message
MessageAndMetadata<byte[], byte[]> messageAndMetadata = it.next();
kafkaMessage = messageAndMetadata.message();
kafkaKey = messageAndMetadata.key();
// Add headers to event (topic, timestamp, and key)
headers = new HashMap<String, String>();
headers.put(KafkaSourceConstants.TIMESTAMP,
String.valueOf(System.currentTimeMillis()));
headers.put(KafkaSourceConstants.TOPIC, topic);
headers.put(KafkaSourceConstants.KEY, new String(kafkaKey));
if (log.isDebugEnabled()) {
log.debug("Message: {}", new String(kafkaMessage));
}
event = EventBuilder.withBody(kafkaMessage, headers);
eventList.add(event);
}
if (log.isDebugEnabled()) {
log.debug("Waited: {} ", System.currentTimeMillis() - batchStartTime);
log.debug("Event #: {}", eventList.size());
}
}
/** 这里读取kafka中的message **/
// If we have events, send events to channel
// clear the event list
// and commit if Kafka doesn't auto-commit
if (eventList.size() > 0) {
// 使用ChannelProcess将Source中读取的数据给各个Channel
// 如果getChannelProcessor().processEventBatch(eventList);发生了异常,eventList不会被清空,而且processEventBatch方法会调用Interceptor处理event中的数据,event中的数据已经被转换。所以下一次会将转换后的event数据再次传给Interceptor。
getChannelProcessor().processEventBatch(eventList);
eventList.clear();
if (log.isDebugEnabled()) {
log.debug("Wrote {} events to channel", eventList.size());
}
if (!kafkaAutoCommitEnabled) {
// commit the read transactions to Kafka to avoid duplicates
consumer.commitOffsets();
}
}
if (!iterStatus) {
if (log.isDebugEnabled()) {
log.debug("Returning with backoff. No more data to read");
}
return Status.BACKOFF;
}
return Status.READY;
} catch (Exception e) {
log.error("KafkaSource EXCEPTION, {}", e);
return Status.BACKOFF;
}
}
上述代码已经加了备注,再重申一下:ChannelProcess的processEventBatch方法会调用Interceptor处理event中的数据。所以如果Channel中的队列满了,那么processEventBatch方法会发生异常,发生异常之后eventList中的没有进入channel的数据已经被Interceptor修改,且不会被清空。因此下次还是会使用这些数据,所以会发生convert json data error错误。
画了一个序列图如下:
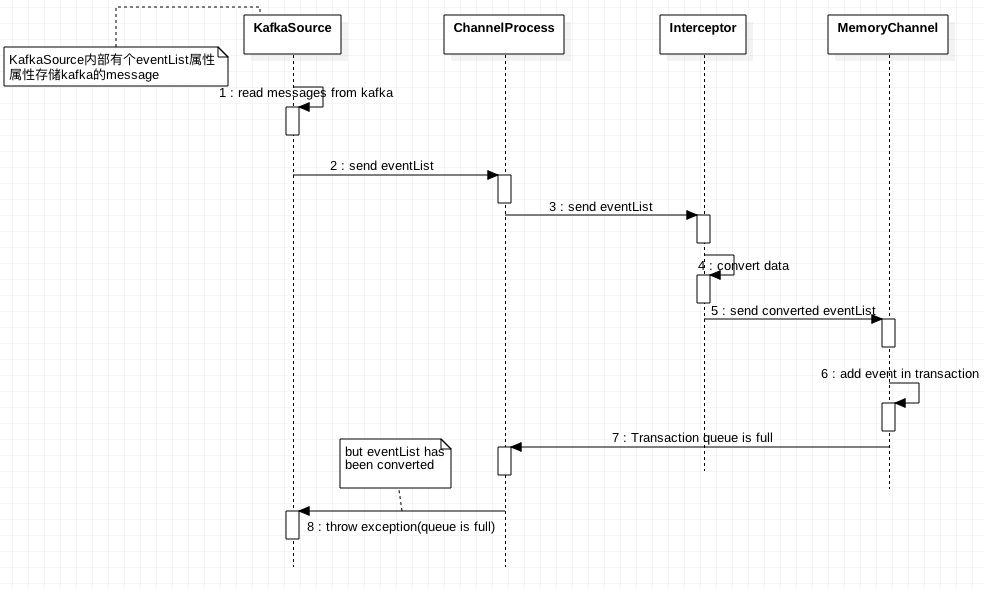
第6步添加event到channel中的时候,队列已满,所以会抛出异常。最终异常被KafkaSource捕捉,但是eventList内部的部分数据已经被interceptor修改过。
多个channel的影响:
如果有多个channel,这个问题也会影响。比如有2个channel,c1和c2。c1的sink没有问题,一直稳定执行,c2对应的sink是一个CustomSink,会有问题。这样c2中的队列迟早会爆满,爆满之后,ChannelProcess批量处理event的时候,由于c2的队列满了,所以Source中的eventList永远不会被清空,eventList永远不会被清空的话,所有的channel都会被影响到,这就好比水源被污染之后,所有的用水都会受到影响。
举个例子:source为s1,c1对应的sink是k1,c2对应的sink是k2。k1和k2的batchSize都是5000,k2处理第4000条数据的时候总会发生异常,进行回滚。k1很稳定。这样c2迟早会爆满,爆满之后s1的eventList一直不能clear,这样也会导致c1一直在处理,所以k1的数据量跟k2一样也会暴增。
要避免本文所说的这一系列情况,最好的做法就是sink必须要加上很好的异常处理机制,不是任何情况都可以rollback的,要根据需求做对应的处理。
