根据项目的经验,介绍几个flume比较有用的功能。
ChannelSelector功能
flume内置的ChannelSelector有两种,分别是Replicating和Multiplexing。
Replicating类型的ChannelSelector会针对每一个Event,拷贝到所有的Channel中,这是默认的ChannelSelector。
replicating类型的ChannelSelector例子如下:
a1.sources = r1
a1.channels = c1 c2 # 如果有100个Event,那么c1和c2中都会有这100个事件
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
Multiplexing类型的ChannelSelector会根据Event中Header中的某个属性决定分发到哪个Channel。
multiplexing类型的ChannelSelector例子如下:
a1.sources = r1
a1.sources.source1.selector.type = multiplexing
a1.sources.source1.selector.header = validation # 以header中的validation对应的值作为条件
a1.sources.source1.selector.mapping.SUCCESS = c2 # 如果header中validation的值为SUCCESS,使用c2这个channel
a1.sources.source1.selector.mapping.FAIL = c1 # 如果header中validation的值为FAIL,使用c1这个channel
a1.sources.source1.selector.default = c1 # 默认使用c1这个channel
Sink的Serializer
HDFS Sink, HBase Sink,ElasticSearch Sink都支持Serializer功能。
Serializer的作用是sink写入的时候,做一些处理。
HDFS Sink的Serializer
在Flume Sink组件分析中一文中,分析过了HDFS写文件的时候使用BucketWriter写数据,BucketWriter内部使用HDFSWriter属性写数据。HDFSWriter是一个处理hdfs文件的接口。
public interface HDFSWriter extends Configurable {
public void open(String filePath) throws IOException;
public void open(String filePath, CompressionCodec codec,
CompressionType cType) throws IOException;
public void append(Event e) throws IOException;
public void sync() throws IOException;
public void close() throws IOException;
public boolean isUnderReplicated();
}
HDFSWriter的结构如下:
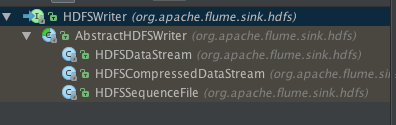
hdfs sink的fileType配置如下:

HDFSDataStream对应DataStream类型,HDFSCompressedDataStream对应CompressedStream,HDFSSequenceFile对应SequenceFile。
以DataStream为例,HDFSDataStream的append方法如下:
@Override
public void append(Event e) throws IOException {
serializer.write(e);
}
这个serializer是HDFSDataStream的属性。是EventSerializer接口类型的属性。HDFSDataStream的append很简单,直接调用serializer的writer方法。
HDFS Sink的Serializer都需要实现EventSerializer接口:
public interface EventSerializer {
public static String CTX_PREFIX = "serializer.";
public void afterCreate() throws IOException;
public void afterReopen() throws IOException;
public void write(Event event) throws IOException;
public void flush() throws IOException;
public void beforeClose() throws IOException;
public boolean supportsReopen();
public interface Builder {
public EventSerializer build(Context context, OutputStream out);
}
}
HDFS Sink默认的serializer是BodyTextEventSerializer类,不配置的话也是使用这个Serializer。
BodyTextEventSerializer的writer方法:
@Override
public void write(Event e) throws IOException {
out.write(e.getBody());
if (appendNewline) {
out.write('\n');
}
}
这就是为什么hdfs sink写数据的时候写完会自动换行的原因。
当然,我们可以定义自定义的Serializer来满足自身的要求。
HBase Sink的Serializer
HBase Sink的Serializer都需要实现HbaseEventSerializer接口。
public interface HbaseEventSerializer extends Configurable,
ConfigurableComponent {
public void initialize(Event event, byte[] columnFamily);
public List<Row> getActions();
public List<Increment> getIncrements();
public void close();
}
HBaseSink的process方法关键代码:
for (; i < batchSize; i++) {
Event event = channel.take();
if (event == null) {
if (i == 0) {
status = Status.BACKOFF;
sinkCounter.incrementBatchEmptyCount();
} else {
sinkCounter.incrementBatchUnderflowCount();
}
break;
} else {
serializer.initialize(event, columnFamily);
actions.addAll(serializer.getActions());
incs.addAll(serializer.getIncrements());
}
}
actions和incs都加入了serializer里的actions和increments。之后会commit这里的actions和increments数据。
HBase默认的Serializer是org.apache.flume.sink.hbase.SimpleHbaseEventSerializer。
我们也可以根据需求定义自定义的HbaseEventSerializer,需要注意的是getActions和getIncrements方法。
HBase Sink会加入这2个方法的返回值,并写入到HBase。
Elasticsearch Sink的Serializer
Elasticsearch Sink的Serializer都需要实现ElasticSearchEventSerializer接口。
public interface ElasticSearchEventSerializer extends Configurable,
ConfigurableComponent {
public static final Charset charset = Charset.defaultCharset();
abstract BytesStream getContentBuilder(Event event) throws IOException;
}
默认的Serializer是org.apache.flume.sink.elasticsearch.ElasticSearchLogStashEventSerializer。
同样,我们也可以根据需求定义自定义的ElasticSearchEventSerialize,就不分析了。
SinkGroup
这个功能暂时还没用到,不过以后可能会用到。
Sink Group的作用是把多个Sink合并成一个。这样的话Sink处理器会根据配置的类型来决定如何使用Sink。比如可以使用load balance,failover策略,或者可以使用自定义的策略来处理。
官方文档Sink Group已经写的很清楚了。
其它
目前还正在用Flume开发一些功能,后续可能会使用一些新的功能,到时候回头更新这篇文章。
