Flume是一个分布式的,效率高的用来收集日志数据的开源框架。它的架构是基于流式数据,有3个重要的组件,分别是Source,Channel和Sink。
Flume架构和特点
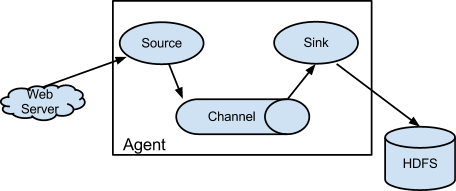
Flume架构图如上,非常简单。
一个Flume的事件(event)表示数据流中的一个单位,它会带有字节数据和可选的字符串属性。一个Flume的agent是一个JVM进程,agent持有3个组件,这3个组件分别是Source,Channel和Sink。
Source组件会消费来自外部的一些事件源数据,这个外部事件源比如是一个web服务器。外部事件源会将事件以某种格式发送给Flume的Source,当Source接收到事件之后,会存储到一个或多个Channel中。
Channel是一个被动型的存储容器,它会一直保留事件直到事件被Sink消费。
Sink会消费Channel里的事件,然后会将事件放到外部仓库里,比如hdfs;或者Sink会转发到下一步Flume agent里做重复的事情。
Source和Sink在agent里异步执行处理channel里的事件。
Flume内部提供了一些常用的Source,Channel和Sink。
举个例子:
Source使用Spooling Directory Source,这个Source会读取文件系统中的文件数据(文件系统中的外部数据相当于之前说的事件源),读取数据之后会放到Channel中,比如使用Memory Channel,将Source接收到的事件存储到内存中,最后使用HDFS这个Sink将Memory Channel中的事件数据写入到hdfs中。
Spooling Directory Source, Memory Channel, HDFS Sink都是Flume内部提供的组件。
Flume非常可靠。每个agent的事件从Source进入到Channel之后,会存储在Channel中。这些事件只有在存储到下一步agent的Channel中或者外部存储仓库(比如hdfs)后,才会在Channel中被移除。
Flume还会使用事务来保证事件处理过程。
Flume还具有很高的可恢复性。事件是存储在channel中的,当使用File Channel的时候,当服务器挂了之后这些文件都还在,但是如果使用的是Memory Channel,就不具备容灾性。
一个简单的Flume配置如下:
# agent名字是a1,有1个source:r1, 1个sink:k1, 1个channel:c1
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 使用netcat source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# 使用 logger sink
a1.sinks.k1.type = logger
# 使用memory channel,容器为1000,事务容量为100
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 将channel讲source和sink关联
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
之后至少还会有3篇Flume相关的文章,分别是讲解Source,Channel和Sink源码相关的文章。
